这篇文章记录glic库中malloc是如何工作的. 主要参考了 Understanding glibc malloc
目录
Memory Allocators
堆内存分配器主流的有.
- dlmalloc – 第一个被广泛使用的通用动态内存分配器;
- ptmalloc2 – glibc 内置分配器的原型;
- jemalloc – FreeBSD & Firefox 所用分配器;
- tcmalloc – Google 贡献的分配器;
- libumem – Solaris 所用分配器;

这篇文章学习glibc库, 代码以glibc-2.28为例
Syscall
malloc() 按传入参数大小决定调用 brk() 或 mmap() .
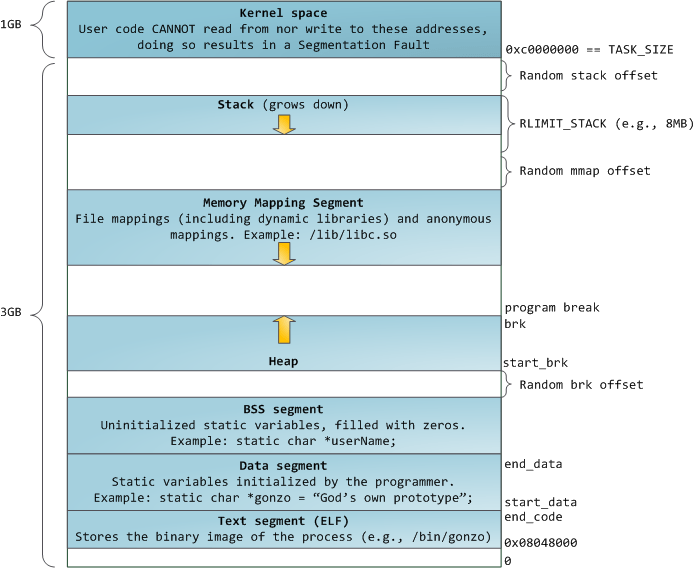
brk
初始状态堆的起点(start_brk)和堆终点(brk)是指向相同的位置的.brk() 通过增加program break location(brk)获得更多内存, 且保留原内存中的数据.
- 当ASLR关闭时, start_brk和brk将指向data/bss段的结尾.
- 当ASLR打开时, start_brk和brk的值将等于data/bss段的结尾加上一个随机的brk偏移.
mmap
mmap() 在 Memory Mapping Segment 处创建清零后的新内存.
内存结构
堆内存管理用到4个数据结构 Arena, Heap, Chunk 和 Bin
Arena > Heap > Chunk
Chunk
chunk是堆内存管理的最小单元, 其结构源码如下
1 |
|
存在最小大小限制: #define MIN_CHUNK_SIZE (offsetof(struct malloc_chunk, fd_nextsize))
chunk最小为 16 bytes(32位环境)/32 bytes(64位环境)
存在对齐要求: #define MALLOC_ALIGNMENT (2 * SIZE_SZ < __alignof__ (long double) ? __alignof__ (long double) : 2 * SIZE_SZ)
chunk对齐大小为 8 bytes(32位环境)/16 bytes(64位环境)
chunk被分为以下4类
Allocated chunk
是已经被分配出去的chunk, 数据结构如下:
1 | chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
| Flags | Meaning |
|---|---|
| A(NON_MAIN_ARENA) | 表示该内存块由线程分配 |
| M(IS_MAPPED) | 表示该块内存通过mmap方式分配 |
| P(PREV_INUSE) | 表示内存中前一内存块已被分配 |
malloc()返回地址为 mem, 即 chunk大小为malloc()传入参数 + chunk头部 然后对齐. |
Free chunk
被释放的chunk, 数据结构如下
1 | chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
fd/bk 指向同一bin中前一个/后一个 chunk
Top Chunk
位于Arena顶部(高地址)的chunk. 当不存在free chunk满足内存分配需求时, 分配器会尝试将top chunk低地址部分分配给用户.
如果top chunk大小小于malloc()传入参数则需要扩展heap.
Last Remainder Chunk
最后一次 small request 中因分割而得到的剩余部分
当用户请求 small chunk 而无法从 small bin 和 unsorted bin 得到服务时, 分配器就会通过扫描 binmaps 找到最小非空 bin. 正如前文所提及的, 如果这样的 bin 找到了, 其中最合适的 chunk 就会分割为两部分: 返回给用户的 User chunk 和添加到 unsorted bin 中的 Remainder chunk.
它有利于改进引用局部性, 即后续对 small chunk 的 malloc 请求可能最终被分配得彼此靠近.
关于 bin 和 binmaps 在后面部分会讲到, 可以先看了再返回来?
Bin
bin是一种记录free chunk的数据结构. bin被分为以下4类:
Fast bin
fastbin 由mfastbinptr fastbinsY[NFASTBINS];存储
在内存分配和释放过程中, fastbin是所有bin中操作速度最快的.
1 | #define NFASTBINS (fastbin_index (request2size (MAX_FAST_SIZE)) + 1) |
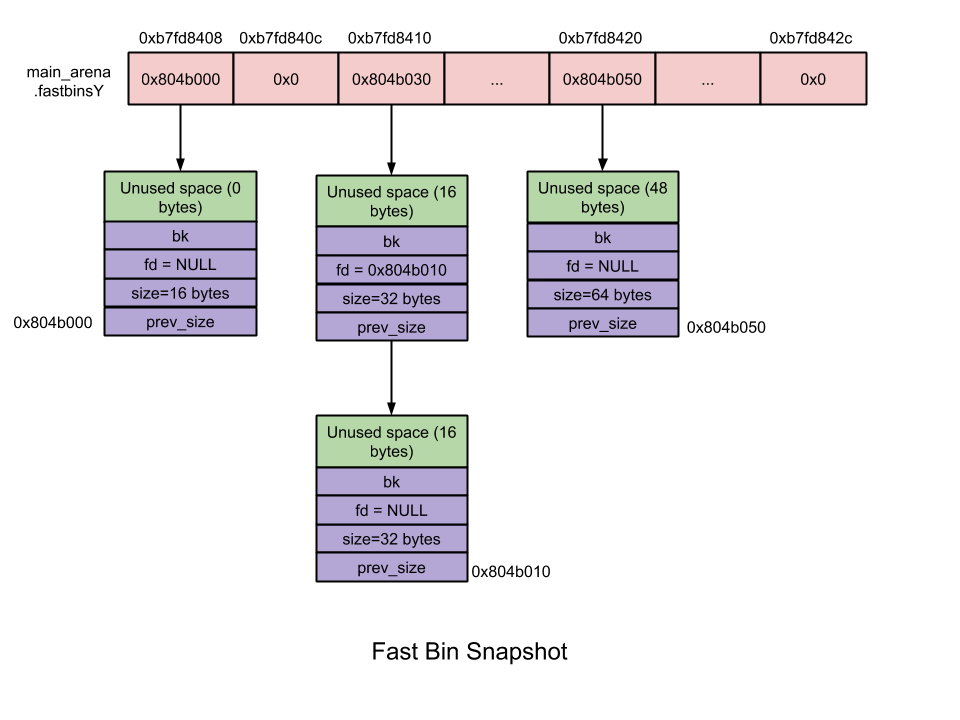
fastbin的特性有:
- fastbin 有10个(32位和64位下都是)
- fastbin 是单链表
- fastbin 中 fastchunk 大小为 16
80 bytes(32位)/32160 bytes(64位), 同一链表中 chunk 大小相同 (不够10个啊???) - fastbin 增减 chunk 发生在链表顶端, 后加入的 chunk 会先被分配出去(LIFO)
- fastbin 中相邻 free chunk 不会被合并, 通过将P标志位置1实现
Unsorted bin
unsortedbin 由mchunkptr bins[NBINS * 2 - 2];中 Bin1 存储
1 | #define NBINS 128 |
被free()的 small chunk 和 large chunk 会被暂存在 unsortedbin 中
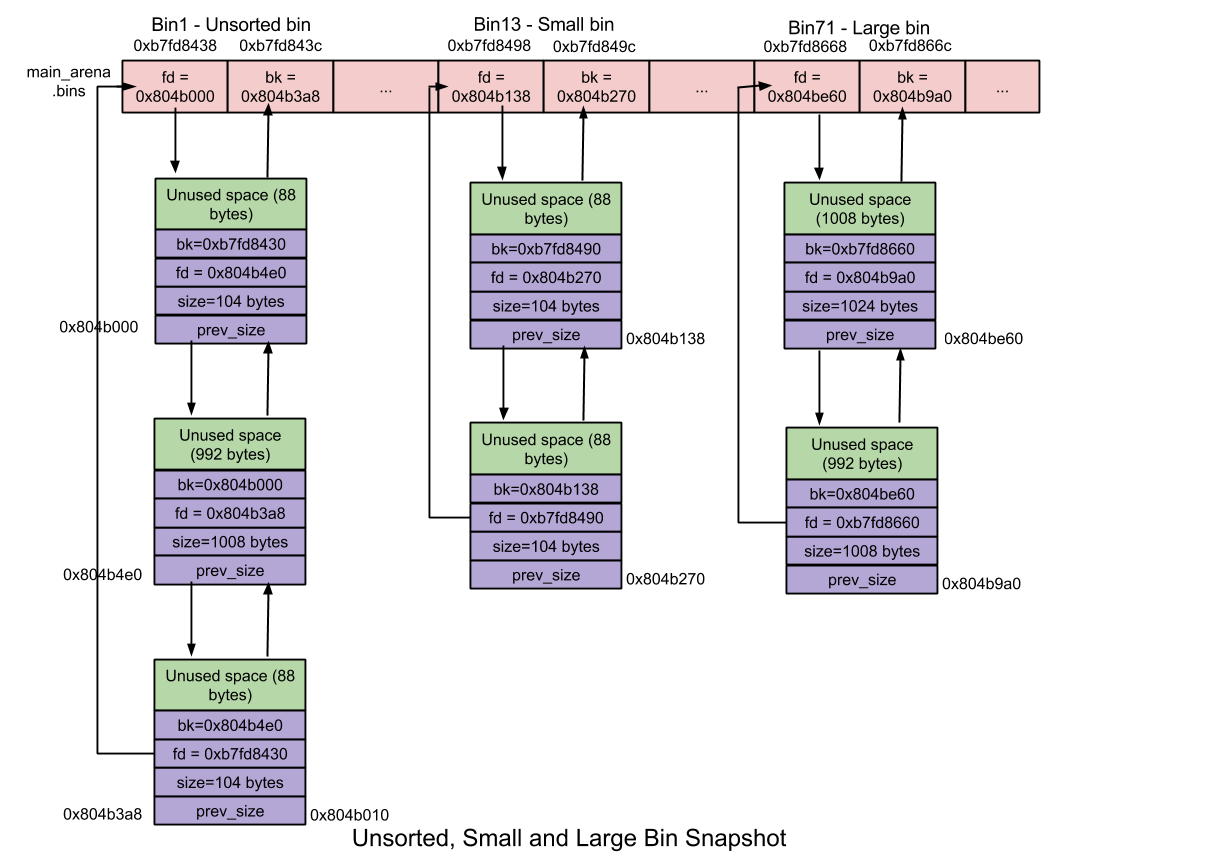
unsortedbin的特性有:
- unsortedbin 有1个
- unsortedbin 是双向循环链表
- unsortedbin 中 chunk 大小无限制
来源:
- freechunk 合并
- last reminder
Small bin
1 | #define in_smallbin_range(sz) ((unsigned long) (sz) < (unsigned long) MIN_LARGE_SIZE) |
smallbin的特性有:
- smallbin 有62个
- smallbin 是双向循环链表
- smallbin 中 smallchunk 大小为 [16, 512)bytes(32) / [32, 1024)(64), 同一链表中 chunk 大小相同
- smallbin 增加 chunk 在链表顶端, 删除 chunk 在链表尾部, 即先加入的 chunk 会先被分配出去(FIFO)
- smallbin 中相邻 chunk 会被合并
Large bin
largebin的特性有:
- largebin 有63个
- largebin 是双向循环链表
- largebin 中 largechunk 大小为 [512, +)bytes(32) / [1024, +)(64), 同一链表中 chunk 大小都在某个范围内, chunk 从顶端到尾端递减保存
- largebin 增加 chunk 在链表顶端, 删除 chunk 在链表尾部, 即先加入的 chunk 会先被分配出去(FIFO)
- largebin 中相邻 chunk 会被合并
从这张表格可以更直观地看出各个bin的特点(?):
| Name | Linked List | I/O | Coalescing | Number | Size(32/64) |
|---|---|---|---|---|---|
| fastbin | Single | LIFO | No | 10 | [16, 80] / [32, 160] |
| unsortedbin | Double Circular | 1 | No limit | ||
| smallbin | Double Circular | FIFO | Yes | 62 | [16, 512) / [32, 1024) |
| largebin | Double Circular | FIFO | Yes | 63 | [512, +) / [1024, +) |
Heap
heap 头部数据结构源码如下:
1 | typedef struct _heap_info |
关于pad: glibc要求 sizeof (heap_info) + 2 * SIZE_SZ 是 MALLOC_ALIGNMENT 的倍数,
1个 Thread Arena 可以有多个 Heap, 当 Thread Arena 中 heap 空间不够时会调用mmap()申请新的 heap 空间作为一个新的 heap 加入原 Arena, 这些 Heap 以单链表的形式穿起来.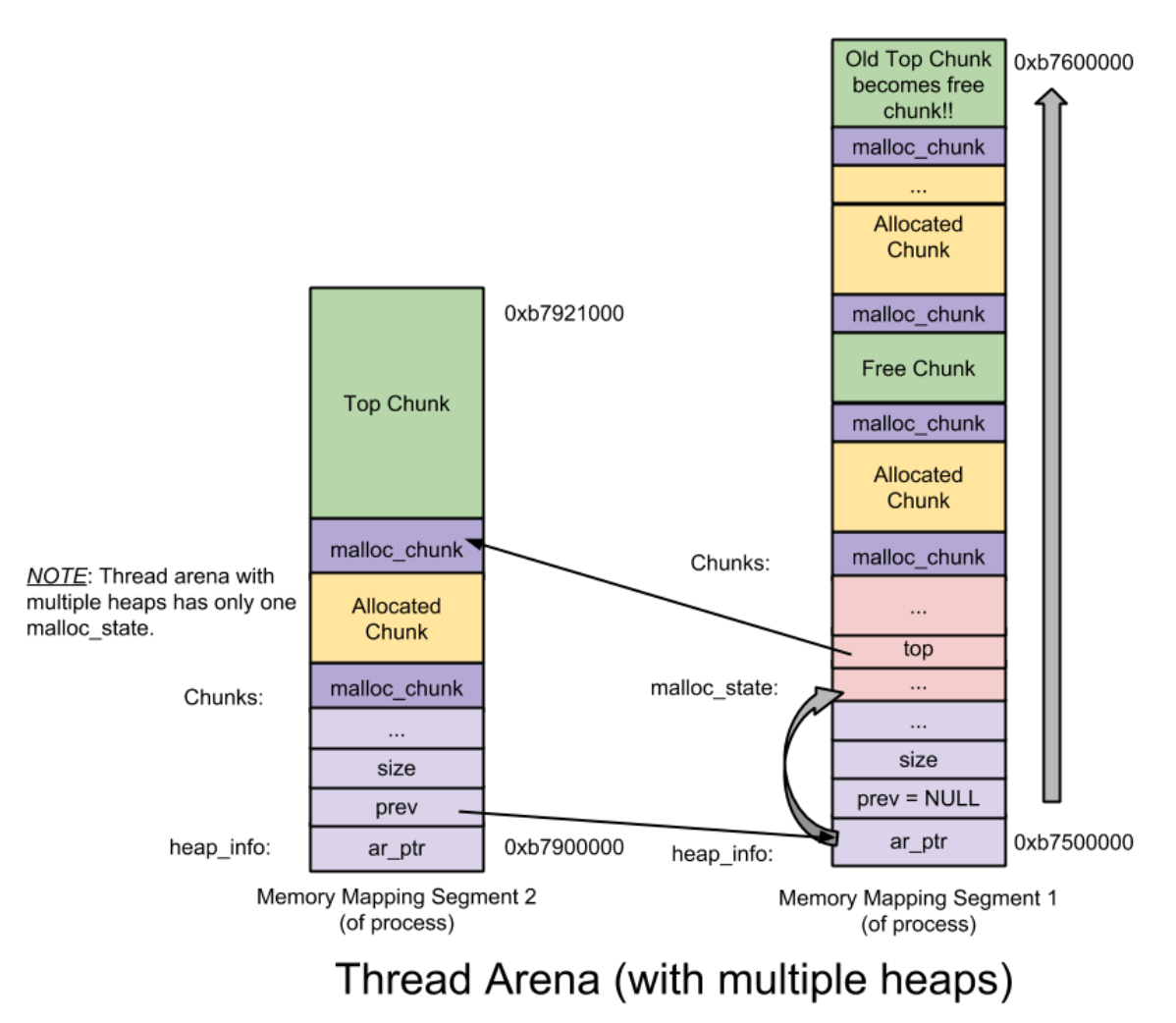
Arena
Arena 是堆内存管理中最大的数据结构, 分为 Main Arena 和 Thread Arena.
Arena 头部数据结构源码如下:
1 | struct malloc_state |
glibc会尽量为一个多线程程序的每个线程都分配1个 Arena, 但是 Arena 个数是有限的: 2倍CPU核数(32位环境) / 8倍CPU核数(64位环境). 当某线程申请使用内存但当前 Arena 个数已达最大值时, glibc首先遍历所有 Arena 并尝试获取它的 mutex, 若成功则该线程与 Arena 原线程共享该 Arena, 否则继续等待直到成功获取 mutex.
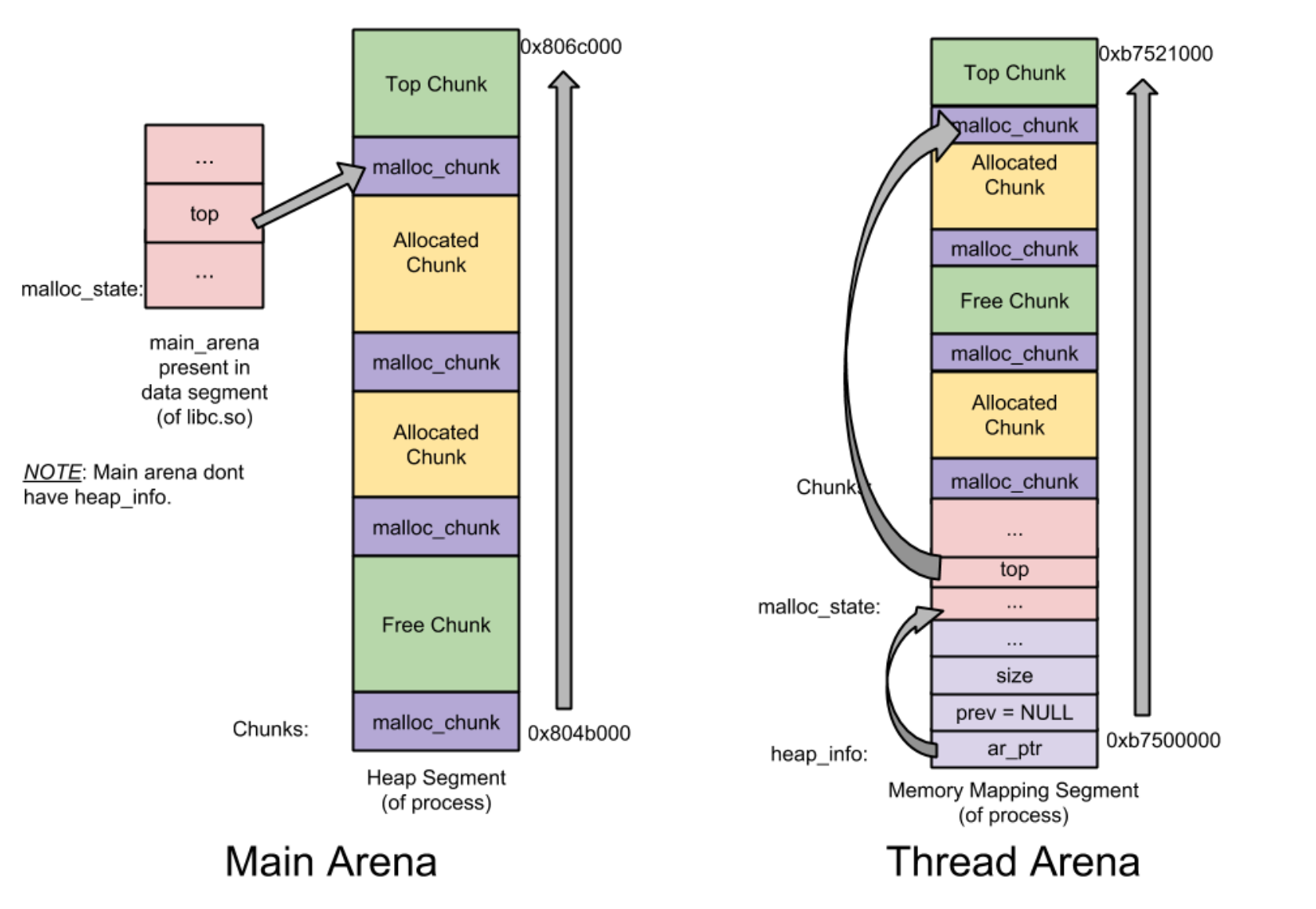
Main Arena 与 Thread Arena 比较表:
| Type | Arena Head | Heap Head | Heap Num | alloc mem |
|---|---|---|---|---|
| Main | global | N | 1 | brk() |
| Thread | inside | Y | many | mmap() |
堆内存管理
malloc()
malloc() 功能主要由 static void *_int_malloc (mstate av, size_t bytes) 实现
- bytes 位于 fastbin 时:
- 根据大小获得fastbin的index
- 根据index获取fastbin中链表的头指针
- 如果头指针为 NULL, 转去smallbin
- 将头指针的下一个chunk地址作为链表头指针
- 检查分配chunk的size是否属于fastbin
- 返回除去chunk_header的地址 return
- bytes 位于 smallbin 时:
- 根据大小获得smallbin的index
- 根据index获取smallbin中双向循环链表的头指针
- 将链表最后一个chunk赋值给victim
- if(victim == 表头)
链表为空, 不从smallbin中分配 - else if(victim == 0)
链表未初始化, 将fastbin中的chunk合并 - else
取出victim, 设置inuse
- if(victim == 表头)
- 检查
victim->bk->fd == victim - 返回除去chunk_header的地址 return
- bytes 位于 largebin 时:
- 根据大小获得largebin的index
- 将fastbin中chunk合并, 加入到unsortbin中
- 对unsortedbin的操作:
- 反向遍历unsortedbin, 检查 2*size_t < chunk_size < 内存总分配量
- unsortedbin的特殊分配:
如果前一步smallbin分配未完成
并且 unsortedbin中只有一个chunk
并且该chunk为 last remainder chunk
并且该chunk大小 > (所需大小 + 最小分配大小)
则切分一块分配 return - 如果请求大小正好等于当前遍历chunk的大小, 则直接分配 return
- 继续遍历, 将合适大小的chunk加入到smallbin中, 向前插入作为链表的第一个chunk. (smallbin中每个链表中chunk大小相同)
- 将合适大小的chunk加入到largebin中, 插入到合适的位置(largebin中每个链表chunk由大到小排列)
- 对largebin的操作:
- 反向遍历largebin, 由下到上查找, 找到合适大小后
- 检查unsortedbin的第一个chunk的bk的fd是否指向自己
- 切分后大小 < 最小分配大小, 返回整个chunk, 会略大于申请大小 return
- 切分后大小 > 最小分配大小, 加入 unsortedbin. return
- 未找到, index+1, 继续寻找
- 反向遍历largebin, 由下到上查找, 找到合适大小后
- top chunk:
- 向系统申请
free()
free()功能主要由static void _int_free (mstate av, mchunkptr p, int have_lock)实现 - 使用
chunksize(p)宏获取 p 的 size - 安全检查:
- chunk的指针地址溢出?
- chunk 的大小 >= MINSIZE(最小分配大小)? 并且地址是否对齐?
- size 位于 fastbin 时:
- 检查下一个chunk的size: 2*size_t < chunk_size < 内存总分配量
- double free检查: 检查当前free的chunk是否与fastbin中的第一个chunk相同,相同则报错
- return
- size 位于其他 bin 时:
- 其他安全检查:
- 检查下一个chunk的size:2*size_t < chunk_size < 内存总分配量
- double free检查:
- chunk 合并
- unsortedbin安全检查:
- return
- 其他安全检查:
REFERENCE
Understanding glibc malloc
Linux堆内存管理深入分析
画类似GitHub那种commit图的工具
Dance In Heap